
در تازهترین پژوهش مشترک با مشارکت تیم تحقیقاتی اپل، مشخص شد که یک ترفند قدیمی سازماندهی یعنی استفاده از فهرست کنترل (چکلیست)، میتواند دقت و توانایی مدلهای زبانی بزرگ (LLM) را بهطور چشمگیری افزایش دهد. در این مقاله، فرآیند طراحی، نتایج و چشماندازهای این روش نوآورانه بررسی میشود.
پسزمینه و نیاز به بهبود کیفیت پاسخها
پس از مرحله پیشآموزش مدلهای زبانی، رایج است که با روشهای پسآموزشی، کیفیت خروجیها ارتقا یابند. رایجترین تکنیک در این حوزه، «یادگیری تقویتی از بازخورد انسانی» (RLHF) است که با اختصاص پاداش یا تنبیه به پاسخهای مدل، آن را به سمت تولید نتایج مطلوبتر سوق میدهد. باوجود اثربخشی RLHF، گاهی مدلها با پاسخهای سطحی یا فریبنده مواجه میشوند که در ظاهر درستاند اما نیاز واقعی کاربران را برآورده نمیکنند.
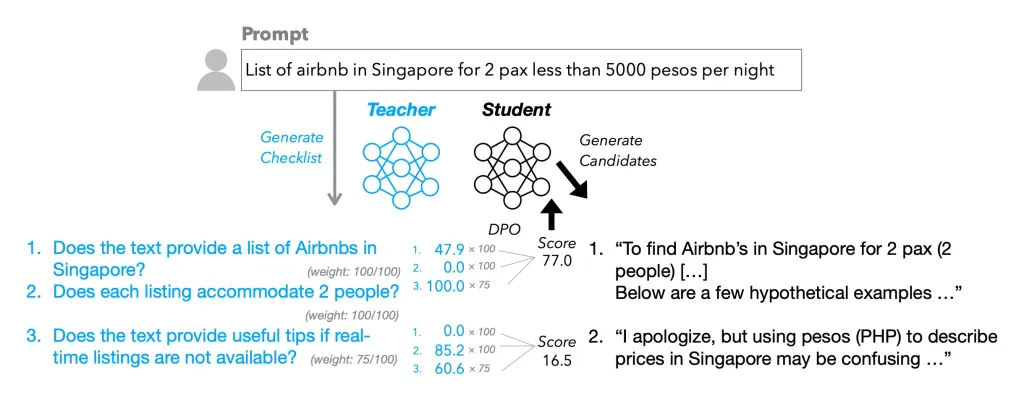
معرفی روش RLCF (یادگیری تقویتی با بازخورد چکلیست)
اپل در مطالعهای با عنوان «Checklists Are Better Than Reward Models For Aligning Language Models» روش جدیدی به نام RLCF را پیشنهاد کرده است. در این شیوه:
- به ازای هر دستورالعمل کاربر، یک چکلیست دقیق شامل معیارهای «بله/خیر» تعریف میشود.
- یک مدل بزرگتر (معمولاً Qwen2.5-72B-Instruct) بهعنوان داور، پاسخهای احتمالی را طبق آن چکلیست امتیازدهی میکند (از صفر تا ۱۰۰).
- شدت اهمیت هر معیار در چکلیست وزندهی شده و بهعنوان سیگنال پاداش برای مدل هدف مورد استفاده قرار میگیرد.
دستاوردهای کلیدی و مقایسه با سایر روشها
اپل این رویکرد را روی مدل Qwen2.5-7B-Instruct و پنج معیار استاندارد آزمایش کرد. نتایج برجسته عبارتند از:
| معیار آزمایش | افزایش امتیاز با RLCF | افزایش امتیاز با سایر روشها |
|---|---|---|
| FollowBench | +4 واحد | نامشخص یا ناچیز |
| InFoBench | +6 واحد | کمتر از +3 واحد |
| Arena-Hard | +3 واحد | کمتر از +1 واحد |
| دیگر بنچمارکها | تا +8.2٪ | بهطور متوسط +2–4٪ |
این موفقیت در تمامی بنچمارکها نشان میدهد که بازخورد چکلیست، قابلیت همترازی (alignment) و پیروی دقیق از دستورالعمل را بهطور قابلملاحظهای بهبود میدهد.
محدودیتها و حوزههای کاربرد آینده
با وجود آثار مثبت، پژوهشگران اپل محدودیتهای زیر را یادآوری کردهاند:
- تمرکز اصلی روی «پیروی از دستورات پیچیده» بوده و ممکن است در کاربردهای دیگر نتیجه متفاوتی داشته باشد.
- استفاده از مدل داور بزرگ برای امتیازدهی، بار محاسباتی و هزینه را افزایش میدهد.
- RLCF بهمنظور «همترازی امنیتی» طراحی نشده است و ممکن است مسائل اخلاقی یا سوءاستفاده را پوشش ندهد.
با این حال، تأثیر مثبت چکلیست در بهبود دقت و ثبات مدلهای زبانی موجب شده است که بسیاری از شرکتها و مراکز تحقیقاتی، این روش را در دستیارهای مجازی و سیستمهای اطلاعرسان خودکار به کار گیرند.
کاربردهای تجاری و تأثیر بر دستیارهای هوشمند
در آینده نزدیک، دستیارهای مجهز به LLM به بخش جداییناپذیر گوشیها، رایانهها و دستگاههای اینترنت اشیا تبدیل خواهند شد. با اتکای کاربران به این هوشها برای انجام امور چندمرحلهای و پیچیده، اطمینان از صحت اجرای دقیق دستورات اهمیت بیشتری پیدا میکند. روش RLCF میتواند:
- میزان خطا در پاسخدهی را کاهش دهد.
- رضایت کاربران و سطح اعتماد به دستیار هوشمند را ارتقا بدهد.
- بستر بهتری برای توسعه قابلیتهای خودکارسازی کسبوکار و خدمات پس از فروش فراهم آورد.
با ورود چکلیستهای هوشمند به فرآیند یادگیری تقویتی، انتظار میرود سرعت پذیرش تجاری LLMها افزایش یابد و امکان بهرهبرداری ایمنتر از آنها در صنعت فناوری بهبود چشمگیری پیدا کند.
استفاده از چکلیستهای منظم و معیارسنجی شده بهعنوان مکملی موثر برای روشهای موجود، راهکار ساده و درعینحال قدرتمندی است که توسعهدهندگان هوش مصنوعی میتوانند فوراً در پروژههای خود پیادهسازی کنند و کیفیت خروجی را به سطح بالاتری برسانند.
من فارغالتحصیل رشته مهندسی نرمافزار هستم و از همان دوران دانشگاه به دنیای تکنولوژی و تحولات آن علاقهمند بودم. فعالیت حرفهای خودم را از سال ۱۳۹۶ با نوشتن مقالات تحلیلی درباره هوش مصنوعی و برنامهنویسی در یک وبلاگ شخصی آغاز کردم. پس از کسب تجربه، به عنوان نویسنده و تحلیلگر با مجلات و وبسایتهای مختلف تکنولوژی همکاری کردم و اکنون به عنوان دبیر سرویس فناوریهای نوظهور در یک مجله معتبر تکنولوژی فعالیت میکنم. تلاش من این است که آخرین پیشرفتها و دستاوردهای این حوزه را به زبانی ساده و کاربردی برای مخاطبان ارائه دهم.


